Next Generation Artificial Intelligence
I was experimenting with different GAN models (Generative Adversarial Networks, if you don’t know) from a while and all the time I was feeling, this time I’m not teaching a machine how to do things, this time I’m asking a machine to be creative, like after showing some pictures asking it to generate similar pictures. (I’ll explain this in a while). It’s like telling a painter to paint something similar to landscape images, or telling a singer to sing similar to Ed Sheeran (off course we’ve to tell him first how landscape looks like or how Ed Sheeran voice sounds like). All this classification of cat and dog, stock prediction regression task, all that seems a decade ago work, even though it’s not. Now with the advancement in Reinforcement Learning and GAN we’ve come to next generation of AI.
So let’s dive deeper to understand GAN first. GAN is based on three concepts -
Generative, Adversarial and Networks So let’s begin with Network first.
Basically the network here means a multilayer perceptron network , though we use more advanced architecture, but for now let’s keep it simple. So there are two networks, Discriminator and Generator. Consider we’ve a cat image dataset (28 * 28 ) and a function that generates uniform noise of given shape (let’s say 1 * 100). So we give this uniform noise to the Generator and it’ll generate a 28 * 28 image from the noise. Let’s call it fake image (initially it’ll be just random noise). So we’ve real image from the cat dataset and fake image from the Generator, now we’ll challenge the Discriminator to tell which one is real image. Obviously in the start Discriminator will easily distinguish between both, but here is the nice concept. From the response of Discriminator, Generator network will alter its weights.You can think of it like Discriminator is telling you the probability of an image to be a real image. So initially it’ll be around 1 for real image and 0 for fake image. So we’ll take the difference and give it to the Generator, therefore the Generator will know how far it is from generating images like real ones and alter it’s weights accordingly.
Here comes the concept of Adversarial. Adversarial basically means a situation involving opposition or conflicts. If you look deeper you’ll see that’s exactly what happening. While Discriminator has to differentiate between real and fake image, Generator is trying to Generate images, that is similar to real image so that Discriminator can no more distinguish between them. That is Generator is just trying to fool the Discriminator while the Discriminator is trying not to get fooled (hence conflict). You can visualise the Generator as forger and Discriminator as Detective.
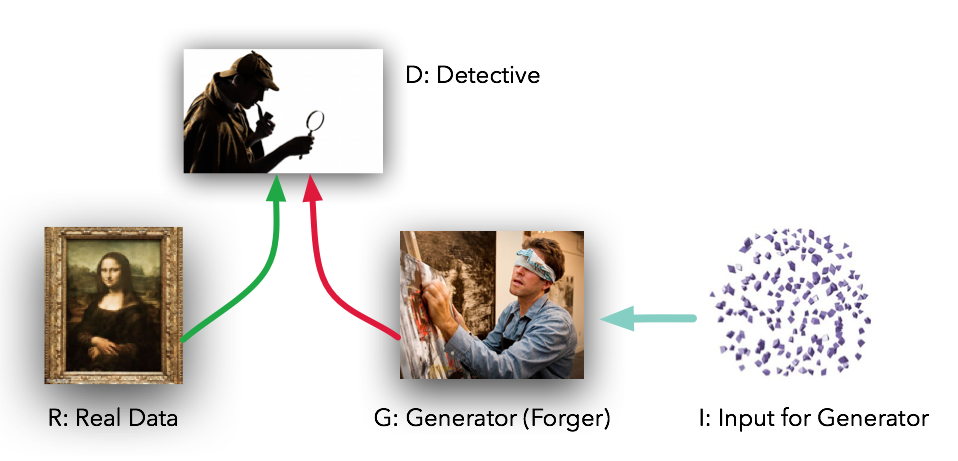
So once you train the two networks enough that the Discriminator is no more able to distinguish between real and fake image, giving probability of 0.5 for each image(optimal condition), that means Generator is generating as good image as the real one. But since the generated images comes from a random noise (that 1*100), no matter how much similar the image would be from the real one, it’ll be a unique image. Hence essentially the Generator is generating brand new images, and hence the word Generative.
So now we’ve a nicer concept of GAN, let me explain what I mean by Next Generation AI. If you see what have we done so far, you’ll notice we’ve just given senses to the machine. Like classifying images and localising the objects (eyes), classifying music (ears), in the robotics field you can push a robot and it’ll be not fall (touch) etc. Although we’re still lacking here with smell and taste.
Now with GAN we’re giving the machine imaginative power. It sounds like a sixth sense for a machine. We can let the machine see some images, and then we’re asking it to generate new unique images, to go in a imaginative world, create and carve new images, something very unique and very realistic as well. Although technically there is actually no imagination here, but looking from outside it does seem so.
With the advancement in GAN we can do hell lot of things, like you can generate new music (yes you can be a good composer with bad taste, although there are many in the industry), you can be a good painter without touching brushes. You might be thinking how is this different from copying, and here it is. While copying things we actually don’t think anything. We just join separate parts (like copying assignment from different friends). But with GAN we can create brand new things. Although all these is not possible yet, but if we can think of them, then we can definitely make it possible.
I would love to end my article by mentioning honourable comment from Yann LeCun (father of CNN if you don’t know) about GAN -
“the most interesting idea in the last 10 years of ML” .
